Redis常见面试题(一)
Redis-常见面试题(一)
1、什么是Redis?(Remote Dictionary Server)
Redis是一个使用C语言编写的,开源的高性能非关系型(NoSQL)的key-value数据库。
Redis可以存储键和五种不同类型的值之间的映射。键的类型只能是字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
与传统数据库不同的是:
(1)Redis的数据是存储在内存中的,所以读写速度非常快。因此Redis被广泛应用于缓存方向,每秒可以处理超过10万次读写操作,是已知最快的key-value数据库。
(2)另外,Redis也经常用来做分布式锁。
(3)除此之外,Redis支持事务、持久化、LUA脚本、LRU驱动事件、多种集群方案。
2、Redis有哪些优缺点?
优点
- 读写性能优异,Redis读的速度是110000次/s,写的速度是81000/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 数据结构丰富,除了支持string类型的value,还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或手动切换前端的ip才能恢复。
主机宕机,宕机前有部分数据未能同步到从机,切换ip后还会引入数据不一致问题,降低了系统的可用性。
Redi较难支持在线扩容,在集群容量达到上限时,在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成很大的浪费。
3、为什么要用Redis/为什么要用缓存?
主要从”高性能”和”高并发”两点来看待这个问题。
高性能
加入用户第一次访问数据库的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次访问这些数据的时候就可以直接从缓存中获取。操作缓存就是直接操作内存,所以速度很快。如果数据库中对应的数据改变后,同步改变缓存中相应的数据即可。

高并发
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不经过数据库。

4、为什么要用Redis而不用map/guava做缓存?
缓存分为本地缓存和分布式缓存。以JAVA为例,使用自带的map或者guava实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着JVM的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用Redis或者memcached之类的称为分布式缓存,在多实例的情况下,各实例公用一份缓存数据,缓存具有一致性。缺点就是需要保持redis或memcached服务的高可用,整个程序架构上较为复杂。
5、Redis为什么这么快?
完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)。
数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的。
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程和多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁的操作,没有因为出现死锁而导致的性能消耗。
使用多路复用I/O模型,非阻塞IO。
使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
6、Redis常见的数据类型
Redis主要有5种数据类型,包括String,List,Set,Zset,Hash。
| 数据类型 | 可存储的值 | 操作 | 应用场景 |
|---|---|---|---|
| String | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 | 做简单的键值对缓存 |
| List | 列表 | 从两端压入或者弹出元素,对单个或者多个元素进行修剪,只保留一个范围内的元素 | 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的数据 |
| Set | 无序集合 | 添加、获取、移除单个元素,检查一个元素是否存在于集合中,计算交集、并集、差集,从集合里面随机获取元素 | 交集,并集,差集的操作,比如交集,可以把两个人的粉丝列表整一个交集 |
| Hash | 包含键值对的无序散列表 | 添加、获取、移除单个键值对,获取所有键值对,检查某个键是否存在 | 结构化的数据,比如一个对象 |
| Zset | 有序集合 | 添加、获取、删除元素,根据分值范围或者成员来获取元素,计算一个键的排名 | 去重但可以排序,如获取排名前几名的用户 |
7、Redis的应用场景
缓存
1
String类型
- 例如:热点数据缓存(报表、明星出轨)、对象缓存、全页缓存、可以提升热点数据的访问数据。
数据共享分布式
1
String类型,因为Redis是分布式的独立服务,可以在多个应用之间共享
例如:分布式session
1
2
3
4<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
分布式锁
1
String类型setnx方法,只有不存在时才能添加成功,返回true
1
2
3
4
5
6
7
8
9
10
11public static boolean getLock(String key) {
Long flag = jedis.setnx(key, "1");
if (flag == 1) {
jedis.expire(key, 10);
}
return flag == 1;
}
public static void releaseLock(String key) {
jedis.del(key);
}全局ID
1
incrby userid 1000 #int类型,incrby,利用原子性
计数器
1
int类型,incr方法
例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
限流
1
int类型。incr方法
以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false
位统计
1
2String类型的bitcount
字符是以8位二进制存储的1
2
3
4
5
6
7
8
9set k1 a
setbit k1 6 1
setbit k1 7 0
get k1
/* 6 7 代表的a的二进制位的修改
a 对应的ASCII码是97,转换为二进制数据是01100001
b 对应的ASCII码是98,转换为二进制数据是01100010
因为bit非常节省空间(1 MB=8388608 bit),可以用来做大数据量的统计。例如:在线用户统计、留存用户统计
1
2
3setbit onlineusers 01
setbit onlineusers 11
setbit onlineusers 20
购物车
1
String或hash。所有String可以做的hash都可以做
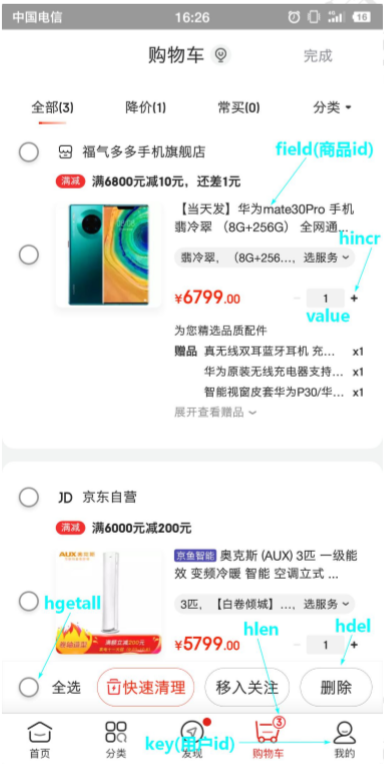
key:用户id;
filed:商品id;
value:商品数量;
+1:hincr;
-1:hdecr;
全选:hgetall;
商品数:hlen。
用户消息时间线
1
list,双向链表,直接作为timeline。插入有序。
消息队列
1
List提供了两个阻塞的弹出操作:blpop/brpop 可以设置超时时间
blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
上面的操作。其实就是java的阻塞队列。学习的东西越多。学习成本越低
队列:先进先除:rpush blpop,左头右尾,右边进入队列,左边出队列
栈:先进后出:rpush brpop
抽奖
1
spop myset #自带一个随机获得值
点赞、签到、打卡
- 假如上面微博id是t1001,用户id是u3001
- 用like:t1001来维护t1001这条微博的所有点赞用户
- 点赞了这条微博:sadd like:t1001 u3001
- 取消点赞:srem like :t1001 u3001
- 是否点赞:sismember like:t1001 u3001
- 点赞的所有用户:smembers like:t1001
- 点赞数:scard like:t1001
商品标签

用tags:i5001来维护商品的所有标签。
- sadd tags:i5001 画面清晰细腻
- sadd tags:i5001 真彩清晰显示屏
- sadd tags:i5001 流程至极
商品筛选
1
2
3
4
5
6// 获取差集
sdiff set1 set2
// 获取交集(intersection )
sinter set1 set2
// 获取并集
sunion set1 set2假如:iphone 11上市
1
2
3
4
5
6
7
8
9
10sadd brand:apple iPhone11
sadd brand:ios iPhone11
sad screensize:6.0-6.24 iPhone11
sad screentype:lcd iPhone 11
#筛选商品,苹果的、ios的、屏幕在6.0-6.24之间的,屏幕材质是LCD屏幕
sinter brand:apple brand:ios screensize:6.0-6.24 screentype:lcd用户关注、推荐模型
1
follow 关注 fans 粉丝
- 相互关注:
- sadd 1:follow 2
- sadd 2:fans 1
- sadd 1:fans 2
- sadd 2:follow 1
- 我关注的人也关注了他:
- sinter:follow 2:fans
- 可能认识的人:
- 用户1可能认识的人(差集):sdiff 2:follow 1:follow
- 用户2可能认识的人(差集):sdiff 1:follow 2:follow
- 相互关注:
排行榜
1
2zincrby hotNews :20190926 1 n6001 #id为6001的新闻点击数加1
zrevrange hotNews:20190926 0 15 withscores #获取今天点击最多的15条
8、Redis持久化(RDB和AOF)
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
各自的优缺点:
RDB:Redis DataBase
RDB是redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存在硬盘中,对应产生的数据文件dump.rdb。通过配置文件中的save参数来定义快照的周期。
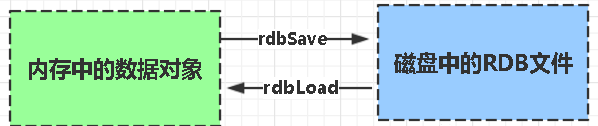
优点:
- 只有一个文件dump.rdb,方便持久化。
- 容灾性好,一个文件可以保存到安全的磁盘。
- 性能最大化,fork子进程来完成写操作,让主进程继续处理命令,所以是IO最大化。使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了reds的高性能。
- 相对于数据集大时,比AOF的启动效率更高。
缺点:
- 数据安全性低。RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
- AOF(appendonly file)持久化方式:是指所有的命令行记录以redis命令请求协议的格式完全持久化存储为aof文件。
AOF:持久化
AOF持久化,则是将Redis执行的每次写命令记录到单独的日志中,当重启Redis会重新将持久化日志中的文件恢复数据。当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
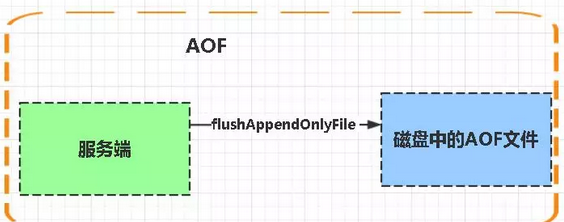
优点:
- 数据安全,aof持久化可以配置appendsync属性,有always,每次进行命令操作就记录到aof文件中一次。
- 通过append模式写文件,即使中途服务器宕机,也可以通过redis-check-aof工具解决数据一致性问题。
- AOF机制的rewrite模式。AOF文件没被rewrite之前,可以删除其中的某些命令。
缺点:
- AOF文件比RDB文件大,恢复速度慢。
- 数据集大的时候,比rdb启动效率低。
区别:
- AOF文件比RDB文件更新频率高,优先使用AOF还原数据。
- AOF比RDB更安全也更大。
- RDB性能比AOF好。
- 如果两个都配了优先加载AOF。
如何选择合适的持久化方式?
- 一般来说,如果想达到足以媲美PostgreSQL的数据安全性,应该同时使用两种持久化功能。在这种情况下,当redis重启的时候,会优先载入AOF文件来恢复原始的数据,因为在通常情况下,AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- 如果你非常关心你的数据,但仍然可以承受数分钟以内数据的丢失,那么你可以使用RDB持久化。
- 有很多用户只使用AOF持久化,但并不推荐这种方式,因为定时生成RDB快照(snopshot)非常便于进行数据库备份,并且RDB恢复数据集的速度也要比AOF恢复的速度要快,除此之外,使用RDB还可以避免AOF程序的bug。
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不适用任何持久化方式。
Redis持久化数据和缓存怎么扩容?
- 如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
- 如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化,否则的话(即redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有redis集群可以做到这样。
9、Redis过期键的删除策略
过期策略通常有一下三种:
- 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即删除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的相应时间和吞吐量。
- 惰性过期:只有当访问一个key时,才会判断该key是否已经过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存很不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
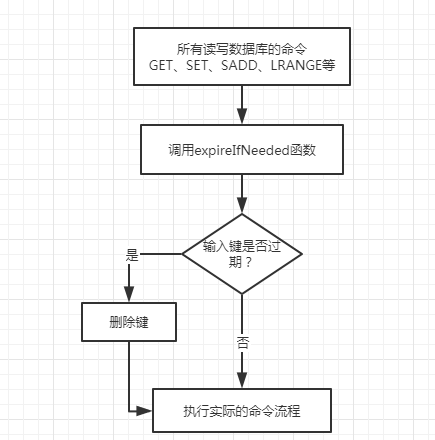
定期过期:activeExpireCycle函数实现。每隔一段时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已经过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是改键的毫秒精度的UNIX时间戳的过期时间。键空间是指该Redis集群中保存的所有键。)
Redis中同时使用了惰性过期和定期过期策略。
Redis key的过期时间和永久有效分别怎么设置?
EXPIRE和PERSIST命令。
我们知道通过expire来设置key 的过期时间,那么对过期的数据怎么处理呢?
除了缓存服务器自带的缓存失效策略之外,我们还可以根据具体的业务需求进行自定义缓存淘汰,常见的策略有两种:
- 定时去清理过期的缓存;
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。