JUC高并发编程-ConcurrentHashmap源码分析 - 多线程与高并发
ConcurrentHashmap源码分析
JDK7 HashMap并发死链
测试代码
注意要在JDK7下运行,否则扩容机制和hash的计算方式都变了
1 | public static void main(String[] args){ |
小结
- 究其原因,是因为在多线程环境下使用了非线程安全的map集合
- JDK8虽然将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能够在多线程环境下能够安全扩容,还会出现其他问题(如扩容丢数据)
JDK8
存储结构
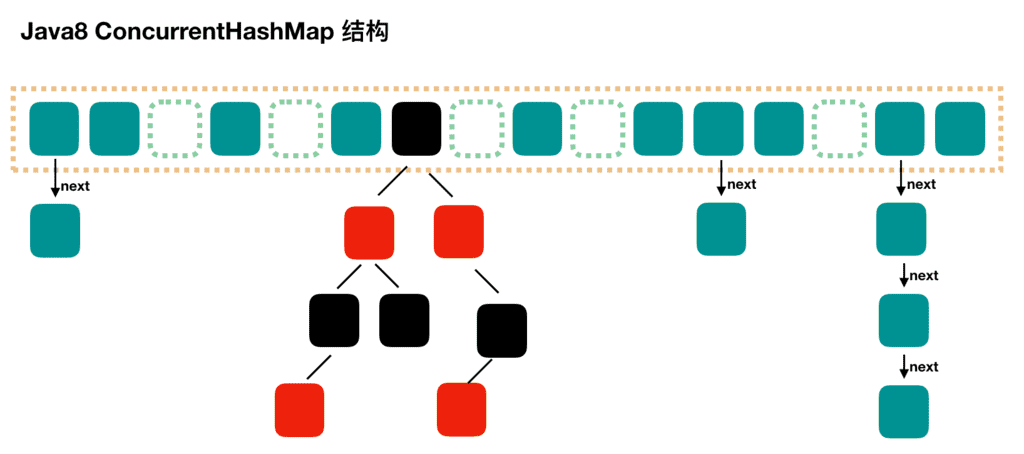
可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。
重要属性和内部类
1 | //默认为0 |
重要方法
1 | //获取Node[]中第i个Node |
构造器分析
可以看到实现了懒惰初始化,在构造方法中仅仅计算了table的大小,以后在第一次使用时才会真正创建
1 | public ConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel){ |
get流程
1 | public V get(Object key){ |
总结一下get过程:
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value。
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
- 如果是链表,遍历查找之。
put流程
以下数组简称(table),链表简称(bin)
1 | public V put(K key, V value) { |
总结:
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于
TREEIFY_THRESHOLD则要执行树化方法,在treeifyBin中会首先判断当前数组长度≥64时才会将链表转换为红黑树。
初始化initTable
1 | /** |
从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量 sizeCtl ,它的值决定着当前的初始化状态。
- -1 说明正在初始化
- -N 说明有N-1个线程正在进行扩容
- 表示 table 初始化大小,如果 table 没有初始化
- 表示 table 容量,如果 table已经初始化。
addCount流程
具体代码如下:
1 | addCount(1L, binCount); |
当插入结束的时候,会调用该方法,并传入一个 1 和 binCount 参数。从方法名字上,该方法应该是对哈希表的元素进行计数的。
一起来看看 addCount 是如何操作的。
1 | // 从 putVal 传入的参数是 1, binCount,binCount 默认是0,只有 hash 冲突了才会大于 1.且他的大小是链表的长度(如果不是红黑数结构的话)。 |
总结一下该方法的逻辑:
x 参数表示的此次需要对表中元素的个数加几。check 参数表示是否需要进行扩容检查,大于等于0 需要进行检查,而我们的 putVal 方法的 binCount 参数最小也是 0 ,因此,每次添加元素都会进行检查。(除非是覆盖操作)
- 判断计数盒子属性是否是空,如果是空,就尝试修改 baseCount 变量,对该变量进行加 X。
- 如果计数盒子不是空,或者修改 baseCount 变量失败了,则放弃对 baseCount 进行操作。
- 如果计数盒子是 null 或者计数盒子的 length 是 0,或者随机取一个位置取于数组长度是 null,那么就对刚刚的元素进行 CAS 赋值。
- 如果赋值失败,或者满足上面的条件,则调用 fullAddCount 方法重新死循环插入。
- 这里如果操作 baseCount 失败了(或者计数盒子不是 Null),且对计数盒子赋值成功,那么就检查 check 变量,如果该变量小于等于 1. 直接结束。否则,计算一下 count 变量。
- 如果 check 大于等于 0 ,说明需要对是否扩容进行检查。
- 如果 map 的 size 大于 sizeCtl(扩容阈值),且 table 的长度小于 1 << 30,那么就进行扩容。
- 根据 length 得到一个标识符,然后,判断 sizeCtl 状态,如果小于 0 ,说明要么在初始化,要么在扩容。
- 如果正在扩容,那么就校验一下数据是否变化了(具体可以看上面代码的注释)。如果检验数据不通过,break。
- 如果校验数据通过了,那么将 sizeCtl 加一,表示多了一个线程帮助扩容。然后进行扩容。
- 如果没有在扩容,但是需要扩容。那么就将 sizeCtl 更新,赋值为标识符左移 16 位 —— 一个负数。然后加 2。 表示,已经有一个线程开始扩容了。然后进行扩容。然后再次更新 count,看看是否还需要扩容。
总结下来看,addCount 方法做了 2 件事情:
- 对 table 的长度加一。无论是通过修改 baseCount,还是通过使用 CounterCell。当 CounterCell 被初始化了,就优先使用他,不再使用 baseCount。
- 检查是否需要扩容,或者是否正在扩容。如果需要扩容,就调用扩容方法,如果正在扩容,就帮助其扩容。
有几个要点注意:
- 第一次调用扩容方法前,sizeCtl 的低 16 位是加 2 的,不是加一。所以 sc == rs + 1 的判断是表示是否完成任务了。因为完成扩容后,sizeCtl == rs + 1。
- 扩容线程最大数量是 65535,是由于低 16 位的位数限制。
- 这里也是可以帮助扩容的,类似 helpTransfer 方法。
size计算流程
size计算实际发生在put,remove改变集合元素的操作之中
- 没有竞争发生,向baseCount累加计数
- 有竞争发生,新建counterCells,向其中的一个cell累加计数
- counterCells初始有两个cell
- 如果计数竞争比较激烈,会创建新的cell来累加计数
1 | public int size() { |
transfer流程
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
JDK7
它维护了一个segment数组,每个segment对应一把锁
- 优点:如果多个线程访问不同的segment,实际是没有冲突的,这与jdk8中类似
- 缺点:Segment数组默认大小为16,这个容量初始化指定后就不能改变了,并不是懒惰初始化。
存储结构
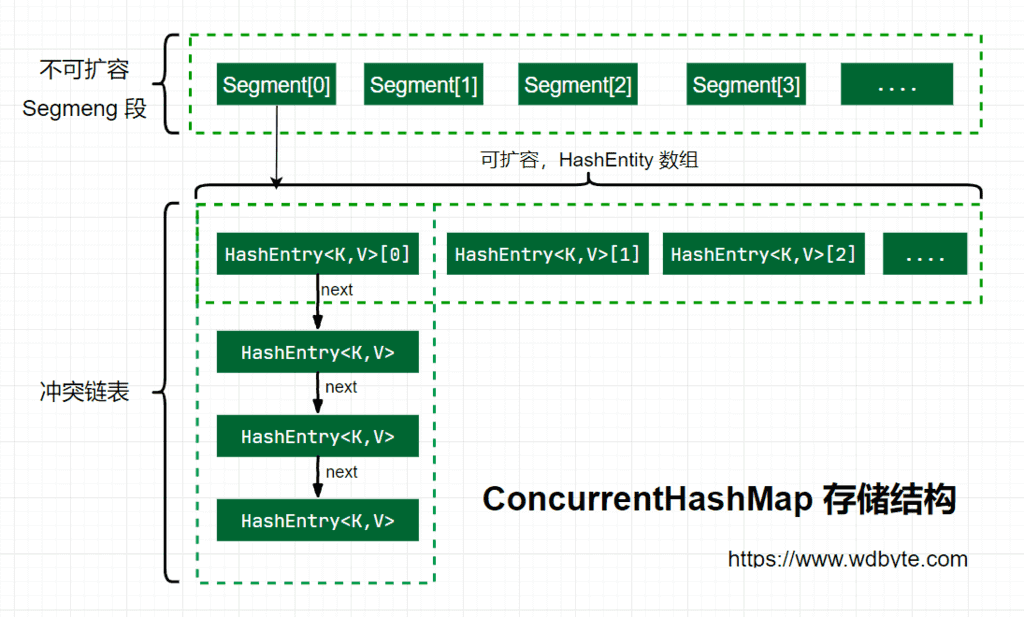
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
构造器分析
通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
1 | /** |
无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
1 | /** |
接着看下这个有参构造函数的内部实现逻辑。
1 |
|
总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。
- 必要参数校验。
- 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无参构造默认值是 16.
- 寻找并发级别 concurrencyLevel 之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。
- 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28.
- 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15.
- *初始化 segments[0]**,**默认大小为 2,负载因子 0.75,**扩容阀值是 20.75=1.5**,插入第二个值时才会进行扩容。
put流程
接着上面的初始化参数继续查看 put 方法源码。
1 | /** |
上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
计算要 put 的 key 的位置,获取指定位置的 Segment。
如果指定位置的 Segment 为空,则初始化这个 Segment。
初始化 Segment 流程:
- 检查计算得到的位置的 Segment 是否为null.
- 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组。
- 再次检查计算得到的指定位置的 Segment 是否为null.
- 使用创建的 HashEntry 数组初始化这个 Segment.
- 自旋判断计算得到的指定位置的 Segment 是否为null,使用 CAS 在这个位置赋值为 Segment.
Segment.put 插入 key,value 值
上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。
1 | final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
tryLock() 获取锁,获取不到使用 scanAndLockForPut 方法继续获取。
计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry 。
遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。
如果这个位置上的 HashEntry 不存在:
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接头插法插入。
如果这个位置上的 HashEntry 存在:
- 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接链表头插法插入。
如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 tryLock() 获取锁。当自旋次数大于指定次数时,使用 lock() 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
1 | private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
扩容rehash
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表头插法插入到指定位置。
1 | private void rehash(HashEntry<K,V> node) { |
有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
get流程
到这里就很简单了,get 方法只需要两步即可。
- 计算得到 key 的存放位置。
- 遍历指定位置查找相同 key 的 value 值。
1 | public V get(Object key) { |
size计算流程
- 计算元素个数前,先不加锁计算两次,如果前后两次结果一样,认为个数返回正确
- 如果不一样,进行重试,重试次数超过3,将所有segment锁住,重新计算个数返回
1 | public int size() { |
总结
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的锁升级。